Fault tolerance
You must give careful consideration to reliability in the architecture frameworks which you build. Building a resilient platform minimizes the future remediation actions for when a failure occurs, and minimizes the possible technical debt that results from uninformed design decisions. This document will provide useful information on how to design and operate a resilient Consul cluster, and what methods and functionalities are at your disposal for this goal.
Consul has a multitude of features that operate both locally, as well as remotely across multiple datacenters that help offer resilient service.
Introduction
Fault tolerance is the ability of a system to continue operating without interruption despite the failure of one or more components. Voting server agent configuration determines Consul's fault tolerance.
Each Consul datacenter depends on a set of Consul voting server agents. The voting servers ensure Consul has a consistent, fault-tolerant state by requiring a majority of voting servers, known as a quorum, to agree upon any state changes. Examples of state changes include: adding or removing services, adding or removing nodes, and changes in service or node health status.
Without a quorum, Consul experiences an outage: it cannot provide most of its capabilities because they rely on the availability of this state information. If Consul has an outage, normal operation can be restored by following the Disaster recovery for Consul clusters guide.
If Consul is deployed with 3 servers, the quorum size is 2. The deployment can lose 1 server and still maintain quorum, so it has a fault tolerance of 1. If Consul is instead deployed with 5 servers, the quorum size increases to 3, so the fault tolerance increases to 2. To learn more about the relationship between the number of servers, quorum, and fault tolerance, refer to the consensus protocol documentation.
Effectively mitigating your risk is more nuanced than just increasing the fault tolerance metric described above. You must consider correlated risks at infrastructure-level - these are occasions which can cause multiple servers to fail at the same time. This means that a single infrastructure-level failure could cause a Consul outage, even if your server-level fault tolerance is 2.
What are the costs of the mitigation? Different mitigation options present different trade-offs for operational complexity, computing cost, and Consul request performance.
Fault tolerance
The following sections explore several options for increasing Consul's fault tolerance. For enhanced reliability, we recommend taking a holistic approach by layering these multiple functionalities together.
- Spread servers across infrastructure availability zones
- Use a minimum quorum size to avoid performance impacts.
- Enterprise Use redundancy zones to improve fault tolerance.
- Use Autopilot to automatically prune failed servers and maintain quorum size.
- Use cluster peering to provide service redundancy.
Availability zones
The cloud or on-premise infrastructure underlying your Consul datacenter may be split into several availability zones.
An availability zone is meant to share no points of failure with other zones by:
- Having power, cooling, and networking systems independent from other zones
- Being physically distant enough from other zones so that large-scale disruptions such as natural disasters (flooding, earthquakes) are very unlikely to affect multiple zones
Availability zones are available in the regions of most cloud providers and in some on-premise installations. If possible, spread your Consul voting servers across 3 availability zones to protect your Consul datacenter from a single zone-level failure. For example, if deploying 5 Consul servers across 3 availability zones, place no more than 2 servers in each zone. If one zone fails, at most 2 servers are lost and quorum will be maintained by the 3 remaining servers.
To distribute your Consul servers across availability zones, modify your infrastructure configuration with your infrastructure provider. No change is needed to your Consul server's agent configuration.
Additionally, you should leverage resources that can automatically restore your compute instance, such as autoscaling groups, virtual machine scale sets, or compute engine autoscaler. Customize autoscaling resources to re-deploy servers into specific availability zones and ensure the desired numbers of servers are available at all times.
Quorum size
For most production use cases, we recommend using a minimum quorum of either 3 or 5 voting servers, yielding a server-level fault tolerance of 1 or 2 respectively.
Even though it would improve fault tolerance, adding voting servers beyond 5 is not recommended because it decreases Consul's performance— it requires Consul to involve more servers in every state change or consistent read.
Consul Enterprise provides a way to improve fault tolerance without this performance penalty. Refer to Redundancy zones for details.
Enterprise Redundancy zones
Use Consul Enterprise redundancy zones to improve fault tolerance without the performance penalty of increasing the number of voting servers.
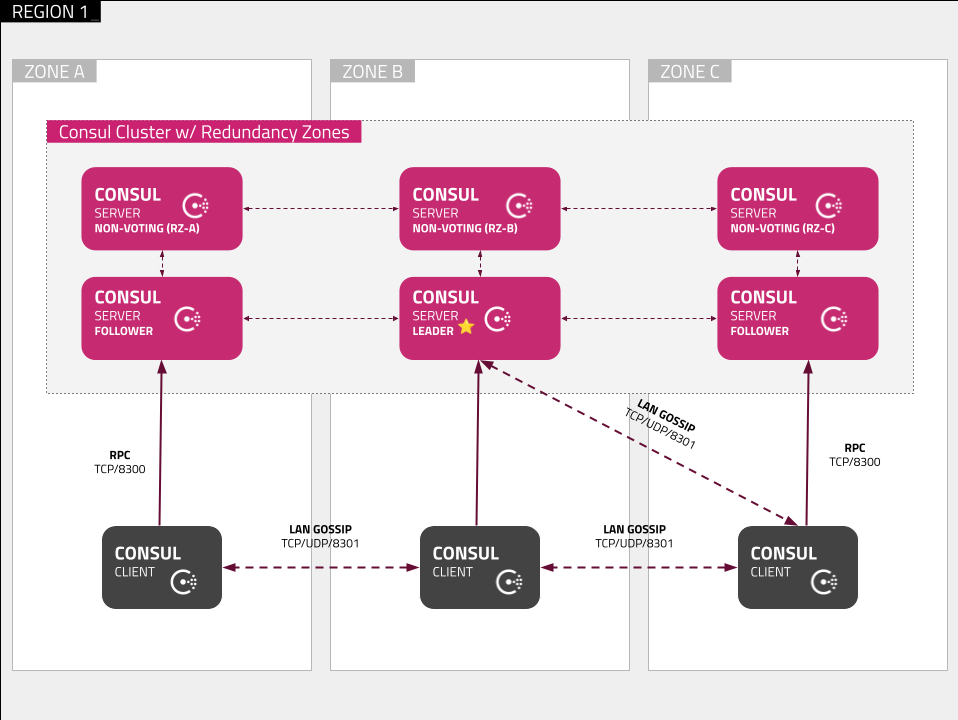
Each redundancy zone should be assigned 2 or more Consul servers. If all servers are healthy, only one server per redundancy zone will be an active voter; all other servers will be backup voters. If a zone's voter is lost, it will be replaced by:
- A backup voter within the same zone, if any. Otherwise,
- A backup voter within another zone, if any.
Consul can replace lost voters with backup voters within 30 seconds in most cases. Because this replacement process is not instantaneous, redundancy zones do not improve immediate fault tolerance— the number of healthy voting servers that can fail at once without causing an outage. Instead, redundancy zones improve optimistic fault tolerance: the number of healthy active and back-up voting servers that can fail gradually without causing an outage.
The relationship between these two types of fault tolerance is:
Optimistic fault tolerance = immediate fault tolerance + the number of healthy backup voters
For example, consider a Consul datacenter with 3 redundancy zones and 2 servers per zone. There will be 3 voting servers (1 per zone), meaning a quorum size of 2 and an immediate fault tolerance of 1. There will also be 3 backup voters (1 per zone), each of which increase the optimistic fault tolerance. Therefore, the optimistic fault tolerance is 4. This provides performance similar to a 3 server setup with fault tolerance similar to a 7 server setup.
We recommend associating each Consul redundancy zone with an infrastructure availability zone to also gain the infrastructure-level fault tolerance benefits provided by availability zones. However, Consul redundancy zones can be used even without the backing of infrastructure availability zones.
For more information on redundancy zones, refer to:
- Redundancy zone documentation for a more detailed explanation
- Redundancy zone tutorial to learn how to use them
Autopilot
Autopilot is a set of functionalities that include cleanup of dead servers, monitoring the state of the Raft protocol in the Consul cluster, and stable server introduction.
When you enable Autopilot's dead server cleanup, Autopilot marks failed servers as Left and removes them from the Raft peer set to prevent them from interfering with the quorum size. Autopilot does that as soon as a replacement Consul server comes online. This is beneficial when server nodes have failed and have been redeployed but Consul considers them as new nodes because their IP address and hostnames have changed. Autopilot keeps the cluster peer set size correct and the quorum requirement simple.
To illustrate the Autopilot advantage, consider a scenario where Consul has a cluster of five server nodes. The quorum is three, which means the cluster can lose two server nodes before the cluster fails. The following events happen:
- Two server nodes fail.
- Two replacement nodes are deployed with new hostnames and IPs.
- The two replacement nodes rejoin the Consul cluster.
- Consul treats the replacement nodes as extra nodes, unrelated to the previously failed nodes.
With Autopilot not enabled, the following happens:
- Consul does not immediately clean up the failed nodes when the replacement nodes join the cluster.
- The cluster now has the three surviving nodes, the two failed nodes, and the two replacement nodes, for a total of seven nodes.
- The quorum is increased to four, which means the cluster can only afford to lose one node until after the two failed nodes are deleted in seventy-two hours.
- The redundancy level has decreased from its initial state.
With Autopilot enabled, the following happens:
- Consul immediately cleans up the failed nodes when the replacement nodes join the cluster.
- The cluster now has the three surviving nodes and the two replacement nodes, for a total of five nodes.
- The quorum stays at three, which means the cluster can afford to lose two nodes before it fails.
- The redundancy level remains the same.
Cluster peering
Linking multiple Consul clusters together to provide service redundancy is the most effective method to prevent disruption from failure. This method is enhanced when you design individual Consul clusters with resilience in mind. Consul clusters interconnect in two ways - WAN federation and cluster peering. We recommend using cluster peering whenever possible.
Cluster peering lets you connect two or more independent Consul clusters using mesh gateways, so that services can communicate between non-identical partitions in different datacenters.
Cluster peering is the preferred way to interconnect clusters because it is operationally easier to configure and manage than WAN Federation. Cluster peering communication between two datacenters runs only on one port on the related Consul Mesh gateway, which makes it operationally easy to expose for routing purposes.
When you use cluster peering to connect admin partitions between datacenters, use Consul’s dynamic traffic management functionalities service-splitter, service-router and service-failover to configure your service mesh to automatically forward or failover service traffic between peer clusters. Consul can then manage the traffic intended for the service and do failover, load-balancing, or redirection.
Cluster peering also extends service discovery across different datacenters independent of service mesh functions. After you've peered datacenters, you can refer to services between datacenters with <service>.virtual.peer.consul in Consul DNS. For Consul Enterprise, your query string may need to include the namespace, partition, or both. Refer to the Consul DNS documentation for details on building virtual service lookups.